

Информация
| Рубрика: | Менеджмент |
|---|---|
| Автор: | intergalactic ==> Средний рейтинг: |
| Дата создания: | 20 мая 2021 г. 19:14 |
| Просмотров: | 512 |
СЕЙЧАС ЧИТАЮТ

2 просмотров 10 комментария

0 просмотров 1 комментария
2 просмотров 1 комментария
2 просмотров 1 комментария

0 просмотров 1 комментария
Время — деньги: анализируй А/В-тесты разумно

Всем привет! Меня зовут Кирилл, я работаю в продуктовом направлении команды Data Science. Сегодня я расскажу о том, как мы в Delivery Club автоматизируем A/B-тестирование. Основная часть статьи посвящена аналитике, но мы кратко затронем и остальные аспекты.
Эпопея с разработкой платформы для А/B-тестов началась чуть больше года назад, когда мы поняли, что наша текущая система работает неправильно и непредсказуемо. Ранее мы управляли A/B-тестами через Firebase Console. С одной стороны, это платформа огромного масштаба и от проверенного производителя, с другой стороны, мы встретили следующие проблемы (которые подтвердились и у наших коллег из других компаний):
- 30% пользователей меняли группу (из теста в контроль или наоборот);
- 15% меняли её два раза и более за эксперимент;
- около 60% пользователей не успевали получить Firebase ID при первом запуске, что для нас было критичным;
- а в самом веб-интерфейсе наши А/А-тесты практически каждый раз сбоили со статусом «заметно сильное улучшение».
После недолгого изучения рынка платных и бесплатных инструментов мы нашли на два отличных варианта:
- Omicron;
- Online Config.
Рассмотрев оба варианта, мы поняли, что лучше разрабатывать свою систему, так как нам нужна максимальная кастомизация всего, что касается:
- режимов работы платформы: QA-тестирование, классический A/B, switchback-тест, feature toggle — специальный режим, по которому конкретную фичу мы можем достаточно гибко включать и выключать в любое время;
- гибкий выбор ID (аргумента функции деления, например, идентификатор клиента).
Важность автоматизации
Ответ на вопрос «Зачем нужна автоматизация?», наверное, довольно очевидный, поэтому разберём другой вопрос: «Насколько большой эффект даёт автоматизация?» На графике видно, как быстро растёт количество запускаемых тестов по месяцам. До автоматизации запуск одного теста и его анализ занимали кучу времени, а теперь это дело нескольких минут. Также автоматизация позволяет избежать ошибок, которые могут возникать при ручном анализе.
Количество запусков тестов через сервис сплитования:

Уже в мае мы запустим 30 экспериментов, и до конца года планируется ещё около 200-300 релизов (примерно 30-50 в месяц), которые будут проводиться через цикл A/B-тестирования.
Пользу от автоматизации мы можем посчитать с точки зрения:
- пропускной способности аналитиков;
- или времени, которое тратится на анализ.
Загруженность команды = Потребность июня / Пропускная способность.
Пропускная способность у команды из 6 человек = 192 человеко-часа аналитиков (6 аналитиков * 8-часовой день * 4 недели). Мы понимаем, что аналитики не работают как роботы 8 часов, и невозможно заниматься только А/B-тестами.
Потребность июня = количество экспериментов * среднее время на эксперимент = 30 экспериментов * 8 человеко-часов = 240 человеко-часов.
То есть по этой формуле загруженность команды = 240/192 = 125%. Мы бы не удовлетворили примерно 25% потребности в наших ресурсах.
С точки зрения экономии мы понимаем, что раньше мы тратили примерно 8 часов аналитика на полный цикл А/B-теста, а сейчас тратим примерно 2-3 часа. Следовательно, только в июне мы сэкономим 30 * (8 часов раньше — 3 часа сейчас) = 150 человеко-часов. Это, в среднем, 10 дашбордов и ещё 5 мини-исследований.
С точки зрения мотивации, рабочий спринт аналитика, состоявший из A/B-тестов, превращается в разнообразный и насыщенный спринт, в котором есть исследования, дашборды, проекты и A/B-тесты!
Впечатляет!
Полный цикл теста
Разберём жизненный путь одного теста. Когда новая фича разработана и аналитики решили, как нужно оценивать её эффект, менеджер заходит в админку и создаёт там необходимый эксперимент, указывая параметры. Основные из них:
- Экран, на котором происходит эксперимент. Этот параметр нужен для того, чтобы правильно разводить параллельные эксперименты, влияющие друг на друга, с помощью так называемой механики «слоёв».
- Выбираем бакеты — одни из 100 случайных групп пользователей, которым мы хотим показывать определённый вариант.
- Даты старта и конца эксперимента.
- К эксперименту также прикрепляются метрики, которые мы хотим собирать автоматически.
После этого в назначенное время эксперимент начинает работать, и пользователи, заходя в приложение, получают от сервиса сплитования одну из версий эксперимента в зависимости от группы, в которую они попали. В течение эксперимента мы отбираем нужную информацию из сырых логов во вспомогательные таблицы, параллельно начиная анализировать результаты, которые в свою очередь визуализируются в форме дашборда.
Создание эксперимента
На самом деле перед созданием эксперимента есть ещё один очень важный этап: менеджер приходит к аналитикам, чтобы они помогли определить, как именно должен проходить эксперимент:
- сколько дней мы хотим его проводить;
- на какой процент пользователей его нужно распространить;
- на какие метрики мы будем ориентироваться во время анализа.
После этого менеджер идëт в админку и в ней указывает нужные параметры эксперимента.



Для аналитики теста особенно важно то, какие метрики мы хотим оценивать. SQL-запрос для рассчитываемой метрики заносится в специальный файл-хранилище метрик. По самому запросу мы понимаем, какие именно данные нужны нам во вспомогательных таблицах в неагрегированном виде. Но об этом подробнее расскажу в следующем разделе.
Сравнение подходов
Давайте разберëмся, какие плюсы есть у такого подхода к созданию экспериментов, и сравним его с другими вариантами.
Мы не делаем из админки очень сложный инструмент. Это важно, потому что ею пользуются, в основном, менеджеры. За всю работу с метриками ответственны аналитики, которые должны заносить SQL-запрос в хранилище метрик, а также давать рекомендации по выбору нужной метрики для конкретного эксперимента. При реализации мы рассматривали другой вариант: максимально параметризировать любую метрику и указывать её параметры в админке — так делают сейчас коллеги из Авито, lnkov рассказал об этом в своей статье на Хабре. Такой подход универсален, однако он сильно усложнил бы менеджерам работу с админкой.
Вспомогательные таблицы
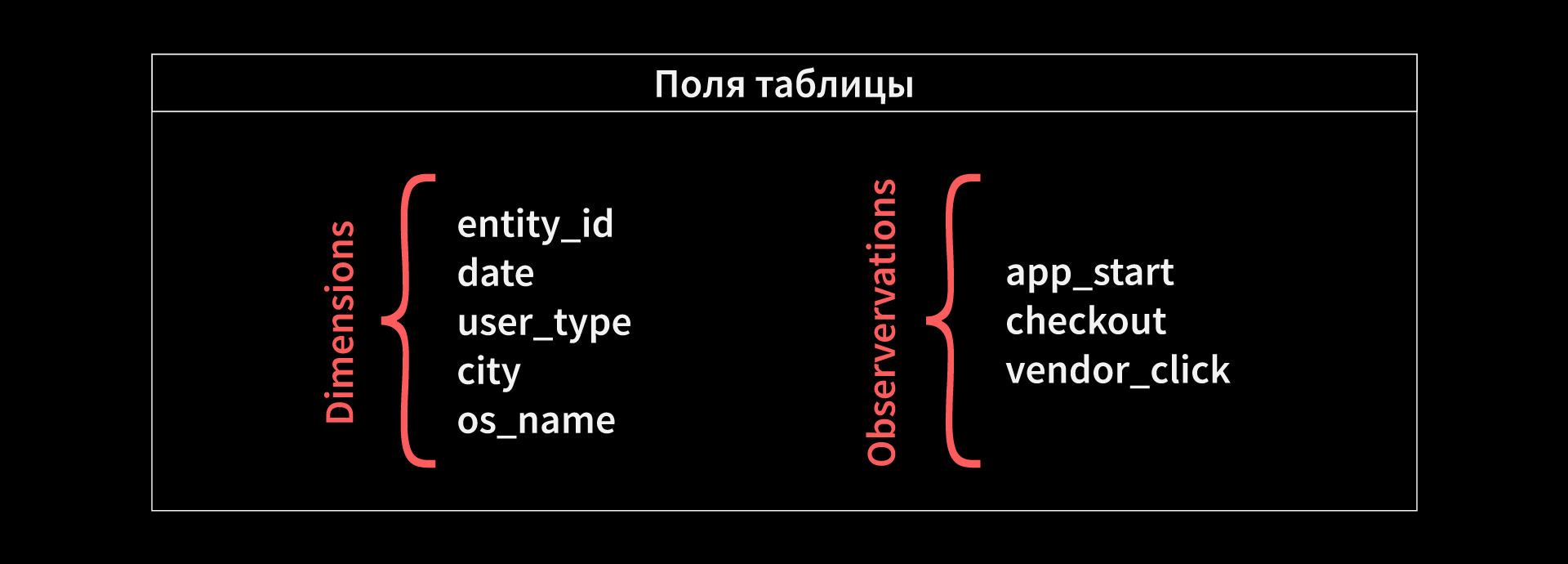
Ещё одним важным элементом анализа А/В-тестов является предварительная подготовка данных, мы подсмотрели эту идею у коллег из Авито, они описывали её в статье, упомянутой выше. Будем называть еë «Вспомогательные таблицы». При обработке данных возникает проблема: в нашем Clickhouse огромные сырые логи, и напрямую обращаться к ним очень долго. Кроме того, в некоторых случаях, если тест раскатывается на почти всех пользователей, данные из сырого лога будут считаться очень долго. Поэтому для каждого эксперимента мы создаём отдельную таблицу, в которую записываем только нужную для этого теста информацию. Еë мы выбираем по коду расчёта метрик из SQL-запроса в нашем хранилище метрик. Например, если в эксперименте мы хотим оценить конверсию из запуска приложения в покупку, то мы будем сохранять информацию о количестве соответствующих событий пользователя. Именно по этим таблицам в будущем и будут рассчитываться эксперименты.

Давайте рассмотрим, как выглядят наши вспомогательные таблицы и почему именно так. Уникальным ключом является сочетание «пользователь, эксперимент, группа», а также набор характеристик пользователя: город, платформа, новый ли это пользователь для данного эксперимента. Зачем нужен такой набор? Допустим, мы знаем, что в начале эксперимента у нас была какая-то ошибка и пользователи делились нечестно, например, на iOS. В таком случае мы можем позже очистить эти данные так, чтобы они не оказывали дополнительное отрицательное воздействие на эксперимент. Также эти разрезы нужны для фильтрации, с их помощью мы можем:
- анализировать эксперимент в конкретных городах;
- исключать определенные дни;
- смотреть, как эксперимент влияет по отдельности на старых и новых пользователей.
Такие таблицы инкрементально обновляются раз в сутки, а их обновление для одного теста длится примерно 3-4 минуты. Это достаточно быстро и позволяет жить в реальности, когда мы запускаем десятки или сотни тестов одновременно. И самое важное — какой эффект вспомогательная таблица оказывает на длительность расчëта эксперимента: до того, как мы начали использовать эти таблицы, наш эксперимент рассчитывался около 30-40 минут, а теперь — примерно в 10 раз быстрее.
К формату «Вспомогательных таблиц» мы пришли не сразу, попутно наступив на некоторые грабли. Самые первые и большие из них — это то, что мы сразу не сделали эти таблицы. Без них данные для одного теста собирались из сырых логов просто невообразимо долго для дальнейшего масштабирования, и если бы каждый день каждый тест считался больше получаса, мы не смогли бы запускать десятки тестов одновременно.
Следующая существенная ошибка: не разбивать наблюдения на даты или сессии, а также другие вспомогательные размерности, например, город или платформа. Эти поля «Вспомогательных таблиц» повышают гибкость анализа, позволяют нормировать пользовательские метрики на дни и делать прочие полезные вещи. Кроме того, не стоит записывать в таблицы сразу все метрики из нашего хранилища: среди метрик, относящихся к тесту, мы выбираем только те события или значения показателей, которые влияют на интересующие метрики. Это позволит сохранить «Вспомогательные таблицы» более компактными и удобными для валидации, ну и, само собой, сэкономит большой объём памяти и времени.
Анализ результатов
Для анализа результатов у нас действует специальный мониторинг. Он запускается раз в день после расчёта вспомогательных таблиц, и состоит из следующих частей:
- Перед расчётом самого теста мы проверяем, нет ли у нас значимых отклонений по распределению по нашим разрезам. Например, мы смотрим, равномерно ли распределились по тесту и контрольной группе iOS-пользователи из Москвы.
- После этого мы формируем наши выборки и проверяем статистическую значимость, а далее записываем результат в специальную таблицу.
Метрики, которые мы оцениваем
Теперь расскажу о метриках которые мы оцениваем, и в целом о метриках, которые могут быть корректно оценены в А/В-экспериментах.
Однажды, когда система сплитования была готова, нам нужно было её протестировать. Мы делали это следующим образом:
- система сплитования делила пользователей на 24 бакета;
- мы считали для заказов этих пользователей основные метрики: средний чек и конверсию;
- попарно сравнивали бакеты, для каждого сравнения получали своё p-value и смотрели на гистограмму.
При выполнении нулевой гипотезы, а в А/А-тестах она заведомо должна выполняться, мы ожидаем увидеть результат как на картинке слева, но, как говорится, реальность полна разочарований, и мы увидели правую картинку. Это означало, что мы находим статистические различия в тестах, в которых их быть не может.

Наша проблема, как оказалось, была в выборе метрик. Проще всего её объяснить на примере среднего чека. Когда мы хотим проверить гипотезу о равенстве средних чеков в группах, уникальное наблюдение в нашей выборке — это один заказ. И у этого подхода есть проблема: заказы одного пользователя — это заведомо сильно зависимые наблюдения. Классические статистические критерии же работают с выборками, где наблюдения независимы, поэтому на наших выборках появились ложные прокрашивания. Если же объединить заказы пользователя в одно наблюдение, сагрегировав, например, средним, то получится то, что мы хотим видеть в А/А-тестах. Так мы пришли к тому, что во всех наших текущих метриках одно наблюдение относится к одному пользователю.


Но это не единственные метрики, которые вообще можно оценивать в пользовательских А/В-тестах. Например, такие глобальные ratio-метрики, как общая конверсия, можно корректно считать с помощью дельта-метода/линеаризации или других приёмов. Подробнее об этом можно почитать в статье коллег из команды VK или посмотреть в докладе команды из Яндекса.
Статистические критерии для анализа «поюзерных» метрик
Теперь пару слов о том, какие статистические критерии мы используем для анализа «поюзерных» метрик:
- Z-тест используется для выборок, в которых наблюдения принимают два значения: 1 или 0. Примером такой метрики может служить индикатор того, была ли у пользователя конверсия из запуска приложения в покупку за период эксперимента. Однако на достаточно больших объёмах нет разницы, что использовать, T-тест или Z-тест.
- Для выборок с сильно скошенными распределениями очень хорошо подходит тест Манна-Уитни. Его можно использовать, когда в выборке нет сильно доминирующей моды, то есть одного наблюдения, которое занимает > 70% всей выборки. Мы используем его для такой метрики, как, например, средний чек. Для неё он является более мощным, чем остальные тесты.
- Классический вариант — это наиболее известный Т-тест Стьюдента. У него есть определенные теоретические ограничения. В частности, мы хотим, чтобы средние подвыборок генеральной совокупности имели нормальное распределение (а не само распределение, что является частым заблуждением). На практике при достаточно больших выборках этот тест показывает себя отлично.
- При сложных распределениях, например, с тяжелыми хвостами, или малых выборках перед использованием Т-теста можно использовать bootstrap. Он помогает сделать распределение более подходящим для применениях других статистических критериев. Главный его недостаток — большие вычислительные затраты и временные ресурсы.

На графиках можно видеть очень крутую визуализацию сравнения мощности теста Манна-Уитни и Т-теста, сделанную коллегами из VK. Здесь варьируется распределение поюзерной конверсии при постоянном распределении просмотров, соответственно, варьируется и распределение заказов. На основной картинке показана ROC-кривая тестов: чем больше площадь под её кривой, тем мощнее наш тест, то есть он реже не замечает изменений, когда они на самом деле есть.


Визуализация результатов

Последним — но не по значимости — этапом в анализе экспериментов является визуализация результатов. На основе полученной таблицы мы строим дашборд в Tableau, в котором показываем текущие результаты по актуальным экспериментам. На нём отображается информация о бизнес-метриках эксперимента и статистически значимой разнице по остальным метрикам в контрольной и тестовой группе. К бизнес-метрикам мы относим глобальные денежные показатели:
- количество человек в группе;
- количество заказов в группе;
- нормированное количество заказов в группе;
- GMV;
- revenue и т.д.
Эти метрики пока не анализируем статистически, но глядя на них можно получить общее представление об эксперименте, выраженное в деньгах. Поюзерные пользовательские метрики же анализируем с помощью статистических критериев, и по ним на дашборде указано, в каких случаях разница между группами статистически значима. Сейчас этим отчётом пользуются, в основном, аналитики, но перед нами стоит задача научить правильно читать его и менеджеров, которые регулярно проводят эксперименты.
Теперь немного о наших планах
В первую очередь мы планируем добавлять поддержку новых сущностей. Мы уже почти готовы анализировать тесты не только на пользователях, но и на логистических зонах. Для таких тестов работает специальная логика switch-back, которая заключается в том, что зоны перемешиваются между группами через определенный интервал, приблизительно равный нескольким часам. Кроме того, очень важно добавлять более продвинутые методы анализа выборок. Например, метод бакетов позволит нам анализировать не только поюзерные метрики, но и глобальные, например, общую конверсию. Напомню, что сейчас мы можем сравнивать только поюзерные метрики. Также есть различные техники типа CUPED, которые позволяют увеличить чувствительность тестов и, как следствие, уменьшить длительность тестирования. Кроме того, мы хотим ускорить сам подсчёт, чтобы иметь возможность резко масштабировать количество временных экспериментов.
Другое важное направление улучшения — это более продвинутая визуализация результатов: мы планируем улучшать наш текущий дашборд, добавлять на него больше полезной информации для аналитиков и менеджеров.

intergalactic
1213
20 мая 2021 г. 19:14